Por Scott Alexander (Astral Codex Ten)

Inteligência Artificial, pode exterminar-nos? (Arte digital: José Oliveira | Fotografias: Pixabay)
Os dois últimos posts que aqui fiz abordaram os riscos a longo termo da IA, por isso pensei em destacar os resultados de um novo questionário de especialistas sobre, exactamente, o que são esses riscos. Tem havido muitos destes questionários recentemente, mas este é um pouco diferente.
Para começar pelo início: de 2012 a 2014, Muller e Bostrom fizeram um questionário sobre o futuro da IA a 550 pessoas que reivindicavam a vários níveis o título de “especialista em IA”. As pessoas da filosofia da IA ou outros campos muito especulativos forneceram números de cerca de 20% de probabilidade de a IA causar uma “catástrofe existencial” (p. ex., a extinção humana); as pessoas da investigação técnica comum sobre a IA forneceram números de cerca de 7%. De 2016 a 2017, Grace et al fizeram um questionário a 1634 especialistas, 5% dos quais previram um resultado extremamente catastrófico. Ambos os questionários eram susceptíveis ao viés de resposta (p. ex., as pessoas com mentes menos especulativas poderiam pensar que o assunto em si era estúpido e nem sequer devolverem o questionário).
O novo artigo 一 Carlier, Clarke, e Schuett (neste momento não é público, lamento, mas pode ler o resumo aqui) 一 não está propriamente a dar continuidade a esta tradição. Em vez de fazer um questionário a todos os especialistas em IA, faz um questionário a pessoas que trabalham na “segurança e governação da IA”, ou seja, pessoas que já se preocupam com o facto de a IA ser potencialmente perigosa, e que dedicaram as suas carreiras a abordar esta questão. Como tal, estavam em média mais preocupadas do que as pessoas dos questionários anteriores, e deram uma probabilidade média de ~10% de catástrofe relacionada com a IA (~5% nos próximos 50 anos, subindo para ~25% se não fizermos um esforço directo para a evitar; as médias eram um pouco mais elevadas do que as medianas). As estimativas de probabilidade individuais dos especialistas variavam de 0,1% a 100% (é assim que se sabe que se está a fazer uma boa futurologia).
Nada disto é realmente surpreendente. O que há de novo aqui é que eles fizeram um questionário aos especialistas sobre as várias formas como a IA poderia correr mal, para ver quais as que mais preocupam os especialistas. Percorro cada uma delas com um pouco mais de detalhe:
- Superinteligência: Este é o cenário “clássico” que iniciou este campo, habilmente descrito por pessoas como Nick Bostrom e Eliezer Yudkowsky. O progresso da IA passa muito rapidamente do nível humano para o nível muito acima do humano, talvez porque as próprias IA ligeiramente acima do nível humano estão a acelerar o processo, ou talvez porque, caso se possa fazer uma IA com um QI de 100 por 10 000 dólares, seja possível fazer uma IA com um QI de 500 por 50 000 dólares. Acaba por se ficar com uma (ou umas quantas) IA superinteligentes de forma completamente inesperada, que dominam tecnologia do futuro distante e utilizam-na de forma imprevisível com base em estruturas de objectivos não testadas.
- A procura de influência que acaba em catástrofe: Descrito por Paul Christiano aqui. As técnicas modernas de aprendizagem de máquina “evoluem” e “seleccionam” as IA que parecem eficientes num determinado objectivo. Mas as IA suficientemente inteligentes com uma grande variedade de objectivos (p. ex., procura de poder) irão tentar parecer eficientes no objectivo que queremos que atinjam, uma vez que essa é a melhor forma de se manterem online e de serem colocadas a controlar recursos importantes, o que as irá ajudar a atingir os seus verdadeiros objectivos. Dependendo da forma como concebemos as estruturas de objectivos da IA, uma percentagem elevada das IA que utilizamos em qualquer momento pode ter objectivos inesperados (incluindo a mera procura do poder). Desde que tudo se mantenha estável, tudo bem; irá continuar a ser do maior interesse das IA alinharem no jogo. Mas se algo de invulgar acontecer, especialmente algo que limite as nossas tentativas de controlar as IA, isso pode fazer com que muitas IA mudem ao mesmo tempo para o seu verdadeiro objectivo, seja esse qual for (ou uma IA muito importante, como uma que controle armas nucleares).
- Seguir a lei de Goodhart até à morte: Descrito por Paul Christiano aqui. Há certas coisas que são fáceis de medir através de um número, como quantos votos um candidato obtém, quanto lucro uma empresa está a obter, ou quantos crimes são denunciados à polícia. Há outras coisas que são difíceis ou impossíveis, como em que medida um candidato é bom, quanto valor uma empresa está a fornecer, ou quantos crimes acontecem. Tentamos usar os primeiros como proxies para os segundos, e na sociedade humana normal isto funciona mais ou menos bem. Mas é muito mais fácil treinar/optimizar as IA para aumentar os números de proxies mensuráveis do que os valores reais. Assim, as IA seriam incentivadas a encontrarem formas de melhorar os proxies (fáceis) sem necessariamente encontrarem formas de satisfazer os nossos valores reais (difíceis) 一 por exemplo, um verdadeiro Robocop, programado para “reduzir a taxa de criminalidade”, poderia tentar tornar o mais difícil possível para as pessoas denunciarem crimes 一 e depois tentar enganar todos os envolvidos para que não detectem este subterfúgio de tal forma que isso faça aumentar a taxa de criminalidade (medida). Conforme as IA assumissem cada vez mais o comando da sociedade, acabaríamos na posição do rei mítico cujo reino está a desmoronar-se à sua volta, mas que nada faz porque os cortesãos lisonjeiros continuam a dizer-lhe que está tudo bem.
- Algum tipo de guerra relacionada com a IA: Descrito por Allan Dafoe aqui. Não uma guerra contra a IA, mas uma guerra entre países humanos normais que, por alguma razão, acontece por causa da IA. Talvez a IA se revele realmente valiosa do ponto de vista militar, e seja qual for o país que a obtenha primeiro decida aproveitar-se da sua vantagem antes que outros o alcancem. Talvez outros países prevejam que isso irá acontecer e lancem um ataque preventivo. Talvez a IA seja capaz de minar a dissuasão nuclear de alguma forma.
- Malfeitores usam a IA para fazer algo maléfico: Talvez as IA mais inteligentes do que os humanos sejam capazes de inventar super-armas, ou armas biológicas realmente eficientes, e terroristas as usem para destruir o mundo. Talvez alguma ditadura (cof! China cof!) descubra como usar a IA a um nível sobre-humano para prever, monitorizar e esmagar a dissidência, fortificando-se para sempre. Talvez os bilionários usem a IA para ganhar muito mais dinheiro e para se tornarem uma oligarquia feudal permanente de uma forma que seja terrível para todos os outros.
- Algo mais: Uma opção que inclua todos os “outros”.
E o vencedor é…
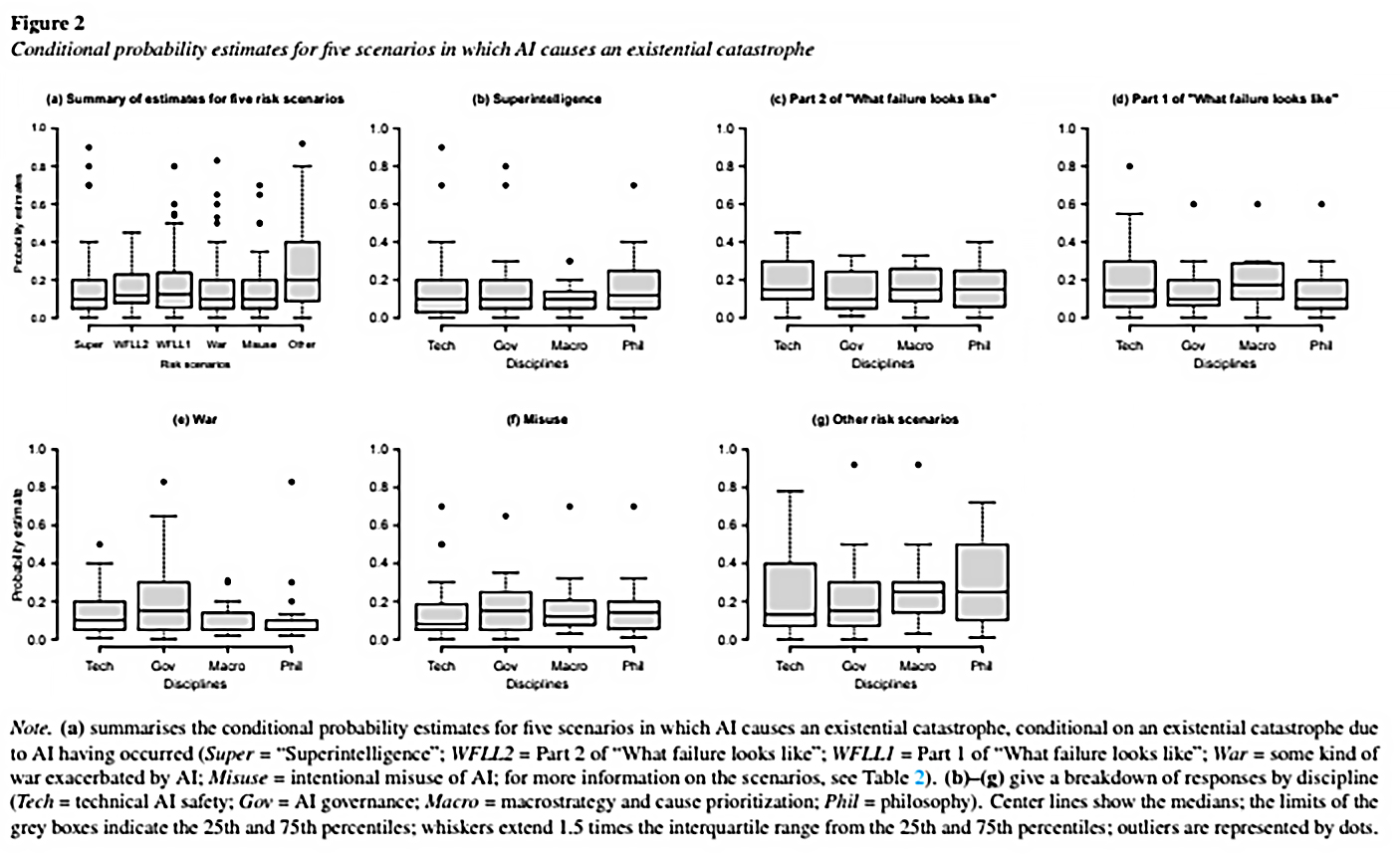
Ninguém em particular! Todos os cenários obtiveram probabilidades iguais, excepto “outros”, que foi a mais elevada.
Houve uma ligeira tendência para as pessoas estarem mais preocupadas com os cenários relacionados com a área em que se encontravam pessoalmente; as pessoas a trabalhar no governo/política estavam mais preocupadas com as guerras e o uso indevido, e as pessoas a trabalhar nas tecnologias estavam mais preocupadas em não conseguir resolver problemas difíceis de optimização. É difícil ler os gráficos, mas isto parece ser da ordem dos 10% vs. 15%, o que me parece ser uma diferença relativamente grande, mesmo que seja pequena em termos absolutos.
Acho isto bastante surpreendente. Teria esperado que cenários muito práticos de “pessoas fazem coisas más com a ajuda da IA ou por causa da IA”, como os cenários 4 e 5, surgissem em posições mais elevadas do que os cenários especulativos de tom futurista como o 1 一 quanto mais não fosse porque, mesmo que a especulação seja inteiramente correcta, as pessoas poderiam matar-nos ao fazerem coisas más antes de chegarmos à parte do futuro em que começam a acontecer coisas estranhas. Mas não, tudo é bastante semelhante.
Para mim, as conclusões interessantes daqui são:
- Mesmo as pessoas que trabalham no problema do alinhamento das IA atribuem maioritariamente uma “baixa” probabilidade (~10%) de que a IA não-alinhada irá resultar na extinção humana,
- Embora algumas pessoas ainda estejam preocupadas com o cenário da superinteligência, as preocupações diversificaram-se muito ao longo dos últimos anos,
- As pessoas que trabalham nesta área não têm uma visão comum específica daquilo que irá correr mal.
Publicado original por Scott Alexander no Blog Astral Codex Ten, a 30 de Julho de 2021.
Tradução de Rosa Costa e José Oliveira.
Descubra mais sobre Altruísmo Eficaz
Assine para receber nossas notícias mais recentes por e-mail.




